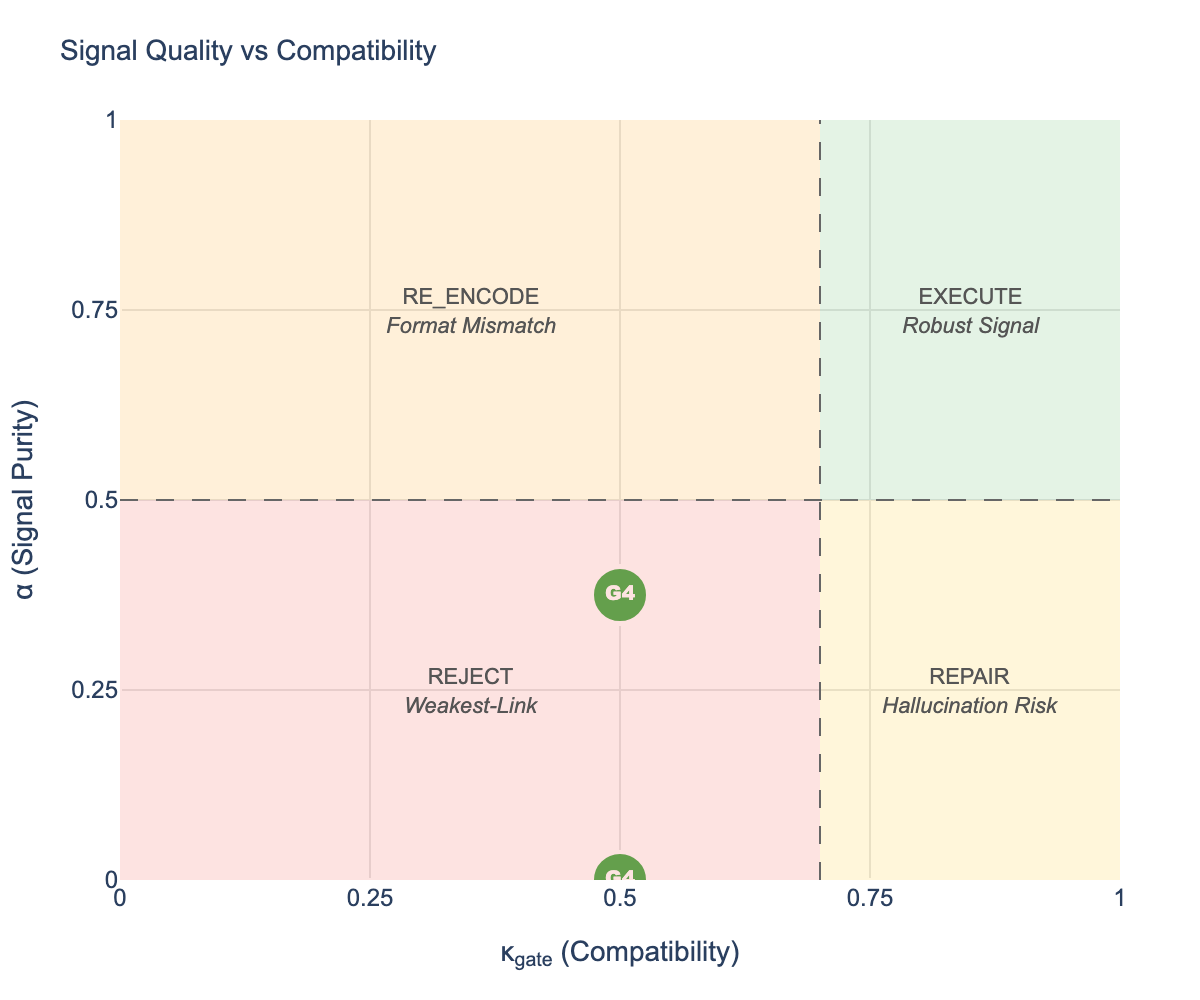
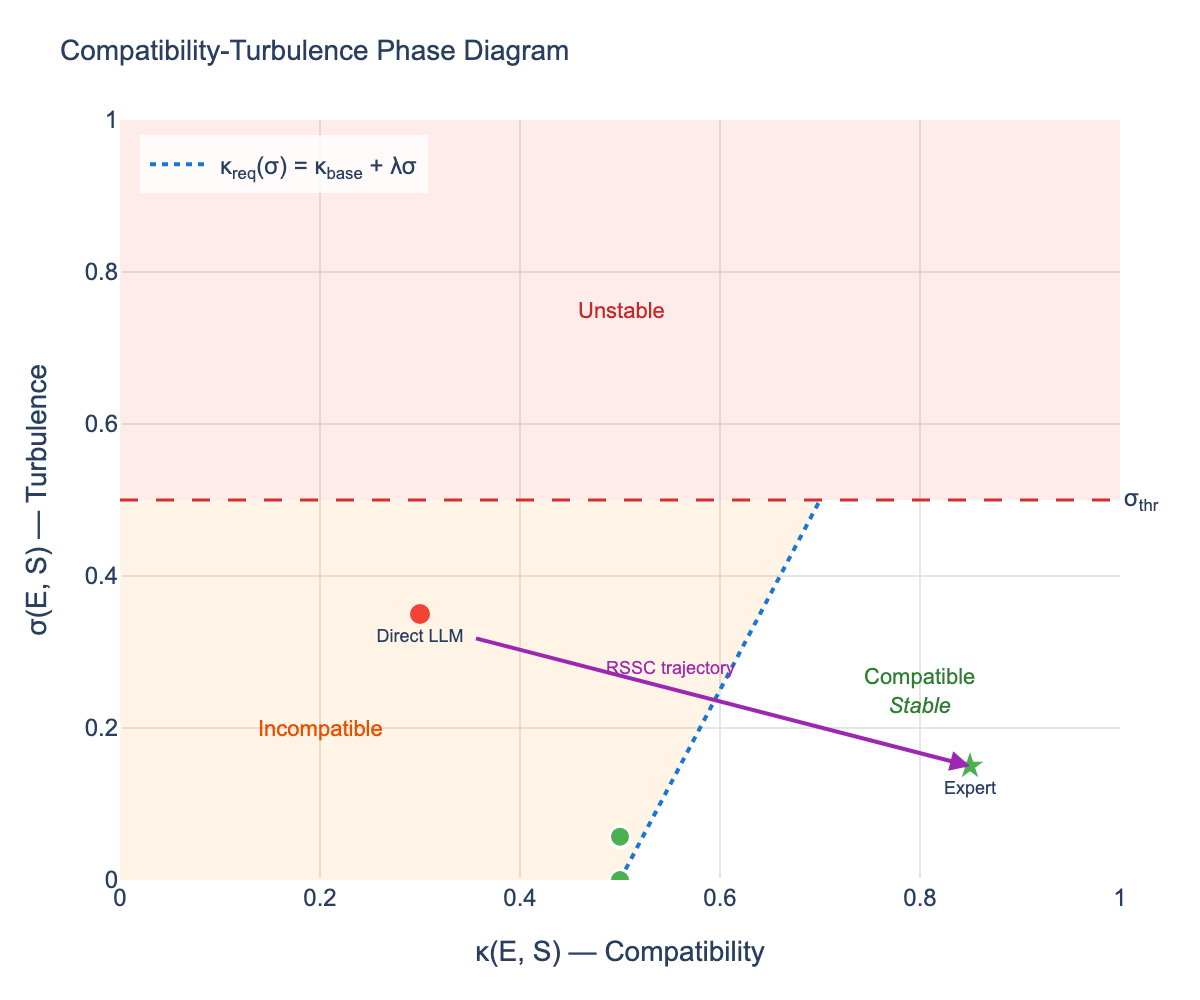
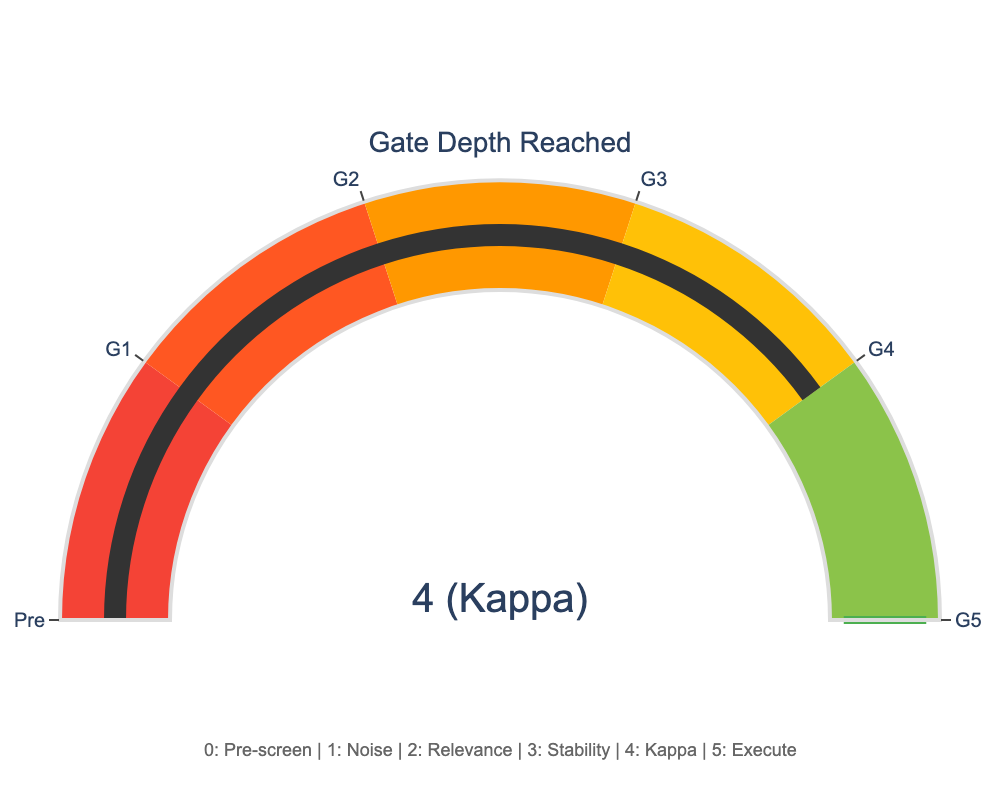
This publication presents a controlled behavioral demonstration of Artificial Coherence Intelligence (ACI), a proposed class of artificial reasoning systems characterized by invariant-bound coherence rather than optimization, prediction, or scale. ACI systems are defined by their ability to preserve identity, proportionality, and internal stability as reasoning unfolds under sustained pressure, contradiction, and uncertainty. The study examines AIngel v2.01 as a reference runtime to assess whether coherence-preserving behavior can be instantiated and observed within a constrained evaluation context. Through structured interaction sequences involving escalating contradiction, ambiguity, ethical tension, and recursive demand, the system exhibits stable correction patterns, sustained orientation, and bounded adaptation across repeated trials. These observations support the feasibility and internal consistency of the proposed ACI classification within a controlled setting. Rather than asserting implementation independence or general-purpose validity, this work focuses on clarifying behavioral criteria by which coherence-oriented reasoning may be identified and evaluated without disclosing construction methods or internal mechanisms. The contribution is classificatory and evidential in scope, demonstrating that coherence can function as an invariant-governed property of reasoning rather than an emergent byproduct of alignment or training scale. The findings are situated within the broader framework of Coherence Science, which treats coherence as a candidate constraint on persistence in adaptive systems operating over long horizons. While limited to a single reference instance, the work provides a grounded starting point for comparative evaluation, replication, and further formalization of coherence-preserving intelligence.
Artificial Intelligence (AI) is transforming the legal domain far beyond prior waves of digitization and workflow automation. Modern AI systems including large language models, multimodal reasoning engines, neural retrieval systems, and predictive analytics—interact directly with core legal activities such as research, drafting, risk assessment, compliance, and public facing legal information services. This white paper presents an original, holistic analysis of AI applicability in law, written specifically for this work and not derived from any public white paper. It examines how AI reshapes legal research, contract workflows, litigation support, regulatory compliance, courtroom practice, and access to justice. The analysis emphasizes limitations related to hallucinations, bias, explainability, and the professional responsibility constraints that govern legal practitioners. The paper argues that AI will not replace legal judgment but will become a pervasive co-pilot within a hybrid human–machine legal ecosystem. We conclude with a governance framework that enables responsible deployment while preserving the legitimacy and fairness of legal systems.
As Large Language Models (LLMs) become more powerful and autonomous, they increasingly face conflicts and dilemmas in many scenarios. We first summarize and taxonomize these diverse conflicts. Then, we model the LLM's preferences to make different choices as a priority graph, where instructions and values are nodes, and the edges represent context-specific priorities determined by the model's output distribution. This graph reveals that a unified stable LLM alignment is very challenging, because the graph is neither static nor necessarily consistent in different contexts. Besides, it also reveals a potential vulnerability: priority hacking, where adversaries can craft deceptive contexts to manipulate the graph and bypass safety alignments. To counter this, we propose a runtime verification mechanism, enabling LLMs to query external sources to ground their context and resist manipulation. While this approach enhances robustness, we also acknowledge that many ethical and value dilemmas are philosophically irreducible, posing a long-term, open challenge for the future of AI alignment.
While locate-then-edit knowledge editing efficiently updates knowledge encoded within Large Language Models (LLMs), a critical generalization failure mode emerges in the practical same-subject knowledge editing scenario: models fail to recall the updated knowledge when following user instructions, despite successfully recalling it in the original edited form. This paper identifies the geometric root of this generalization collapse as a fundamental conflict where the inner activation drifts induced by prompt variations exceed the model's geometric tolerance for generalization after editing. We attribute this instability to a dual pathology: (1) The joint optimization with orthogonal gradients collapses solutions into sharp minima with narrow stability, and (2) the standard covariance constraint paradoxically acts as a Covariance Trap that amplifies input perturbations. To resolve this, we introduce RoSE (Robust Same-subject Editing), which employs Isotropic Geometric Alignment to minimize representational deviation and Hierarchical Knowledge Integration to smooth the optimization landscape. Extensive experiments demonstrate that RoSE significantly improves instruction-following capabilities, laying the foundation for robust interactive parametric memory of LLM agents.
Reinforcement learning for code generation relies on verifiable rewards from unit test pass rates. Yet high-quality test suites are scarce, existing datasets offer limited coverage, and static rewards fail to adapt as models improve. Recent self-play methods unify code and test generation in a single model, but face a inherent dilemma: white-box access leads to self-collusion where the model produces trivial tests for easy rewards, yet black-box restriction yields generic tests that miss implementation-specific bugs. We introduce Code-A1, an adversarial co-evolution framework that jointly optimizes a Code LLM and a Test LLM with opposing objectives. The Code LLM is rewarded for passing more tests, while the Test LLM is rewarded for exposing more defects. This architectural separation eliminates self-collusion risks and safely enables white-box test generation, where the Test LLM can inspect candidate code to craft targeted adversarial tests. We further introduce a Mistake Book mechanism for experience replay and a composite reward balancing test validity with adversarial difficulty. Experiments on Qwen2.5-Coder models demonstrate that Code-A1 achieves code generation performance matching or exceeding models trained on human-annotated tests, while significantly improving test generation capability.
Explainability is widely regarded as essential for trustworthy artificial intelligence systems. However, the metrics commonly used to evaluate counterfactual explanations are algorithmic evaluation metrics that are rarely validated against human judgments of explanation quality. This raises the question of whether such metrics meaningfully reflect user perceptions. We address this question through an empirical study that directly compares algorithmic evaluation metrics with human judgments across three datasets. Participants rated counterfactual explanations along multiple dimensions of perceived quality, which we relate to a comprehensive set of standard counterfactual metrics. We analyze both individual relationships and the extent to which combinations of metrics can predict human assessments. Our results show that correlations between algorithmic metrics and human ratings are generally weak and strongly dataset-dependent. Moreover, increasing the number of metrics used in predictive models does not lead to reliable improvements, indicating structural limitations in how current metrics capture criteria relevant for humans. Overall, our findings suggest that widely used counterfactual evaluation metrics fail to reflect key aspects of explanation quality as perceived by users, underscoring the need for more human-centered approaches to evaluating explainable artificial intelligence.
Standard optimization theories struggle to explain grokking, where generalization occurs long after training convergence. While geometric studies attribute this to slow drift, they often overlook the interaction between the optimizer's noise structure and landscape curvature. This work analyzes AdamW dynamics on modular arithmetic tasks, revealing a ``Spectral Gating'' mechanism that regulates the transition from memorization to generalization.
We find that AdamW operates as a variance-gated stochastic system. Grokking is constrained by a stability condition: the generalizing solution resides in a sharp basin ($λ_{max}^H$) initially inaccessible under low-variance regimes. The ``delayed'' phase represents the accumulation of gradient variance required to lift the effective stability ceiling, permitting entry into this sharp manifold.
Our ablation studies identify three complexity regimes: (1) \textbf{Capacity Collapse} ($P < 23$), where rank-deficiency prevents structural learning; (2) \textbf{The Variance-Limited Regime} ($P \approx 41$), where generalization waits for the spectral gate to open; and (3) \textbf{Stability Override} ($P > 67$), where memorization becomes dimensionally unstable. Furthermore, we challenge the "Flat Minima" hypothesis for algorithmic tasks, showing that isotropic noise injection fails to induce grokking. Generalization requires the \textit{anisotropic rectification} unique to adaptive optimizers, which directs noise into the tangent space of the solution manifold.
Accurate process supervision remains a critical challenge for long-horizon robotic manipulation. A primary bottleneck is that current video MLLMs, trained primarily under a Supervised Fine-Tuning (SFT) paradigm, function as passive "Observers" that recognize ongoing events rather than evaluating the current state relative to the final task goal. In this paper, we introduce PRIMO R1 (Process Reasoning Induced Monitoring), a 7B framework that transforms video MLLMs into active "Critics". We leverage outcome-based Reinforcement Learning to incentivize explicit Chain-of-Thought generation for progress estimation. Furthermore, our architecture constructs a structured temporal input by explicitly anchoring the video sequence between initial and current state images. Supported by the proposed PRIMO Dataset and Benchmark, extensive experiments across diverse in-domain environments and out-of-domain real-world humanoid scenarios demonstrate that PRIMO R1 achieves state-of-the-art performance. Quantitatively, our 7B model achieves a 50% reduction in the mean absolute error of specialized reasoning baselines, demonstrating significant relative accuracy improvements over 72B-scale general MLLMs. Furthermore, PRIMO R1 exhibits strong zero-shot generalization on difficult failure detection tasks. We establish state-of-the-art performance on RoboFail benchmark with 67.0% accuracy, surpassing closed-source models like OpenAI o1 by 6.0%.
Can AI make progress on important, unsolved mathematical problems? Large language models are now capable of sophisticated mathematical and scientific reasoning, but whether they can perform novel research is still widely debated and underexplored. We introduce HorizonMath, a benchmark of over 100 predominantly unsolved problems spanning 8 domains in computational and applied mathematics, paired with an open-source evaluation framework for automated verification. Our benchmark targets a class of problems where discovery is hard, requiring meaningful mathematical insight, but verification is computationally efficient and simple. Because these solutions are unknown, HorizonMath is immune to data contamination, and most state-of-the-art models score near 0%. Existing research-level benchmarks instead rely on formal proof verification or manual review, both of which are expensive to scale. Using this platform, we find two problems for which GPT 5.4 Pro proposes solutions that improve on the best-known published results, representing potential novel contributions (pending expert review). We release HorizonMath as an open challenge and a growing community resource, where correct solutions to problems in the unsolved problem classes could constitute novel results in the mathematical literature.
Existing behavioral alignment techniques for Large Language Models (LLMs) often neglect the discrepancy between surface compliance and internal unaligned representations, leaving LLMs vulnerable to long-tail risks. More crucially, we posit that LLMs possess an inherent state of moral indifference due to compressing distinct moral concepts into uniform probability distributions. We verify and remedy this indifference in LLMs' latent representations, utilizing 251k moral vectors constructed upon Prototype Theory and the Social-Chemistry-101 dataset. Firstly, our analysis across 23 models reveals that current LLMs fail to represent the distinction between opposed moral categories and fine-grained typicality gradients within these categories; notably, neither model scaling, architecture, nor explicit alignment reshapes this indifference. We then employ Sparse Autoencoders on Qwen3-8B, isolate mono-semantic moral features, and targetedly reconstruct their topological relationships to align with ground-truth moral vectors. This representational alignment naturally improves moral reasoning and granularity, achieving a 75% pairwise win-rate on the independent adversarial Flames benchmark. Finally, we elaborate on the remedial nature of current intervention methods from an experientialist philosophy, arguing that endogenously aligned AI might require a transformation from post-hoc corrections to proactive cultivation.
Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
Acceleration methods for diffusion models (e.g., token merging or downsampling) typically optimize synthesis quality under reduced compute, yet often ignore discriminative capacity. We revisit token compression with a joint objective and present BiGain, a training-free, plug-and-play framework that preserves generation quality while improving classification in accelerated diffusion models. Our key insight is frequency separation: mapping feature-space signals into a frequency-aware representation disentangles fine detail from global semantics, enabling compression that respects both generative fidelity and discriminative utility. BiGain reflects this principle with two frequency-aware operators: (1) Laplacian-gated token merging, which encourages merges among spectrally smooth tokens while discouraging merges of high-contrast tokens, thereby retaining edges and textures; and (2) Interpolate-Extrapolate KV Downsampling, which downsamples keys/values via a controllable interextrapolation between nearest and average pooling while keeping queries intact, thereby conserving attention precision. Across DiT- and U-Net-based backbones and ImageNet-1K, ImageNet-100, Oxford-IIIT Pets, and COCO-2017, our operators consistently improve the speed-accuracy trade-off for diffusion-based classification, while maintaining or enhancing generation quality under comparable acceleration. For instance, on ImageNet-1K, with 70% token merging on Stable Diffusion 2.0, BiGain increases classification accuracy by 7.15% while improving FID by 0.34 (1.85%). Our analyses indicate that balanced spectral retention, preserving high-frequency detail and low/mid-frequency semantics, is a reliable design rule for token compression in diffusion models. To our knowledge, BiGain is the first framework to jointly study and advance both generation and classification under accelerated diffusion, supporting lower-cost deployment.
Recently, Multimodal Large Language Models (MLLMs) have been widely integrated into diffusion frameworks primarily as text encoders to tackle complex tasks such as spatial reasoning. However, this paradigm suffers from two critical limitations: (i) MLLMs text encoder exhibits insufficient reasoning depth. Single-step encoding fails to activate the Chain-of-Thought process, which is essential for MLLMs to provide accurate guidance for complex tasks. (ii) The guidance remains invariant during the decoding process. Invariant guidance during decoding prevents DiT from progressively decomposing complex instructions into actionable denoising steps, even with correct MLLM encodings. To this end, we propose Endogenous Chain-of-Thought (EndoCoT), a novel framework that first activates MLLMs' reasoning potential by iteratively refining latent thought states through an iterative thought guidance module, and then bridges these states to the DiT's denoising process. Second, a terminal thought grounding module is applied to ensure the reasoning trajectory remains grounded in textual supervision by aligning the final state with ground-truth answers. With these two components, the MLLM text encoder delivers meticulously reasoned guidance, enabling the DiT to execute it progressively and ultimately solve complex tasks in a step-by-step manner. Extensive evaluations across diverse benchmarks (e.g., Maze, TSP, VSP, and Sudoku) achieve an average accuracy of 92.1%, outperforming the strongest baseline by 8.3 percentage points.
Reasoning LLMs-as-Judges, which can benefit from inference-time scaling, provide a promising path for extending the success of reasoning models to non-verifiable domains where the output correctness/quality cannot be directly checked. However, while reasoning judges have shown better performance on static evaluation benchmarks, their effectiveness in actual policy training has not been systematically examined. Therefore, we conduct a rigorous study to investigate the actual impact of non-reasoning and reasoning judges in reinforcement-learning-based LLM alignment. Our controlled synthetic setting, where a "gold-standard" judge (gpt-oss-120b) provides preference annotations to train smaller judges, reveals key differences between non-reasoning and reasoning judges: non-reasoning judges lead to reward hacking easily, while reasoning judges can lead to policies that achieve strong performance when evaluated by the gold-standard judge. Interestingly, we find that the reasoning-judge-trained policies achieve such strong performance by learning to generate highly effective adversarial outputs that can also score well on popular benchmarks such as Arena-Hard by deceiving other LLM-judges. Combined with our further analysis, our study highlights both important findings and room for improvements for applying (reasoning) LLM-judges in non-verifiable LLM post-training.
Cross-entropy (CE) training provides dense and scalable supervision for language models, but it optimizes next-token prediction under teacher forcing rather than sequence-level behavior under model rollouts. We introduce a feature-matching objective for language-model fine-tuning that targets sequence-level statistics of the completion distribution, providing dense semantic feedback without requiring a task-specific verifier or preference model. To optimize this objective efficiently, we propose energy-based fine-tuning (EBFT), which uses strided block-parallel sampling to generate multiple rollouts from nested prefixes concurrently, batches feature extraction over these rollouts, and uses the resulting embeddings to perform an on-policy policy-gradient update. We present a theoretical perspective connecting EBFT to KL-regularized feature-matching and energy-based modeling. Empirically, across Q&A coding, unstructured coding, and translation, EBFT matches RLVR and outperforms SFT on downstream accuracy while achieving a lower validation cross-entropy than both methods.
Machine-learned interatomic potentials (MLIPs) are deployed for high-throughput materials screening without formal reliability guarantees. We show that a single MLIP used as a stability filter misses 93% of density functional theory (DFT)-stable materials (recall 0.07) on a 25,000-material benchmark. Proof-Carrying Materials (PCM) closes this gap through three stages: adversarial falsification across compositional space, bootstrap envelope refinement with 95% confidence intervals, and Lean 4 formal certification. Auditing CHGNet, TensorNet and MACE reveals architecture-specific blind spots with near-zero pairwise error correlations (r ≤ 0.13; n = 5,000), confirmed by independent Quantum ESPRESSO validation (20/20 converged; median DFT/CHGNet force ratio 12x). A risk model trained on PCM-discovered features predicts failures on unseen materials (AUC-ROC = 0.938 +/- 0.004) and transfers across architectures (cross-MLIP AUC-ROC ~ 0.70; feature importance r = 0.877). In a thermoelectric screening case study, PCM-audited protocols discover 62 additional stable materials missed by single-MLIP screening - a 25% improvement in discovery yield.
Synthetic data has become essential for training code generation models, yet it introduces significant noise and hallucinations that are difficult to detect with current metrics. Existing data selection methods like Instruction-Following Difficulty (IFD) typically assess how hard a model generates an answer given a query ($A|Q$). However, this metric is ambiguous on noisy synthetic data, where low probability can distinguish between intrinsic task complexity and model-generated hallucinations. Here, we propose QAQ, a novel data selection framework that evaluates data quality from the reverse direction: how well can the answer predict the query ($Q|A$)? We define Reverse Mutual Information (RMI) to quantify the information gain about the query conditioned on the answer. Our analyses reveal that both extremes of RMI signal quality issues: low RMI indicates semantic misalignment, while excessively high RMI may contain defect patterns that LLMs easily recognize. Furthermore, we introduce a selection strategy based on the disagreement between strong and weak models to identify samples that are valid yet challenging. Experiments on the WarriorCoder dataset demonstrate that selecting just 25% of data using stratified RMI achieves comparable performance to full-data training, significantly outperforming existing data selection methods. Our approach highlights the importance of bidirectional semantic coherence in synthetic data curation, offering a scalable pathway to reduce computational costs without sacrificing model capability.
Constructing scientific multimodal document reasoning datasets for foundation model training involves an inherent trade-off among scale, faithfulness, and realism. To address this challenge, we introduce the synthesize-and-reground framework, a two-stage pipeline comprising: (1) Claim-Centric QA Synthesis, which generates faithful, isolated QA pairs and reasoning on focused segments, and (2) Document-Scale Regrounding, which programmatically re-embeds these pairs into full-document tasks to ensure realistic complexity. Using this framework, we construct SciMDR, a large-scale training dataset for cross-modal comprehension, comprising 300K QA pairs with explicit reasoning chains across 20K scientific papers. We further construct SciMDR-Eval, an expert-annotated benchmark to evaluate multimodal comprehension within full-length scientific workflows. Experiments demonstrate that models fine-tuned on SciMDR achieve significant improvements across multiple scientific QA benchmarks, particularly in those tasks requiring complex document-level reasoning.
This article, a lightly adapted version of Perplexity's response to NIST/CAISI Request for Information 2025-0035, details our observations and recommendations concerning the security of frontier AI agents. These insights are informed by Perplexity's experience operating general-purpose agentic systems used by millions of users and thousands of enterprises in both controlled and open-world environments. Agent architectures change core assumptions around code-data separation, authority boundaries, and execution predictability, creating new confidentiality, integrity, and availability failure modes. We map principal attack surfaces across tools, connectors, hosting boundaries, and multi-agent coordination, with particular emphasis on indirect prompt injection, confused-deputy behavior, and cascading failures in long-running workflows. We then assess current defenses as a layered stack: input-level and model-level mitigations, sandboxed execution, and deterministic policy enforcement for high-consequence actions. Finally, we identify standards and research gaps, including adaptive security benchmarks, policy models for delegation and privilege control, and guidance for secure multi-agent system design aligned with NIST risk management principles.
Intelligent systems across physics, language and perception often exhibit factorisable structure, yet are typically modelled by monolithic neural architectures that do not explicitly exploit this structure. The separable neural architecture (SNA) addresses this by formalising a representational class that unifies additive, quadratic and tensor-decomposed neural models. By constraining interaction order and tensor rank, SNAs impose a structural inductive bias that factorises high-dimensional mappings into low-arity components. Separability need not be a property of the system itself: it often emerges in the coordinates or representations through which the system is expressed. Crucially, this coordinate-aware formulation reveals a structural analogy between chaotic spatiotemporal dynamics and linguistic autoregression. By treating continuous physical states as smooth, separable embeddings, SNAs enable distributional modelling of chaotic systems. This approach mitigates the nonphysical drift characteristics of deterministic operators whilst remaining applicable to discrete sequences. The compositional versatility of this approach is demonstrated across four domains: autonomous waypoint navigation via reinforcement learning, inverse generation of multifunctional microstructures, distributional modelling of turbulent flow and neural language modelling. These results establish the separable neural architecture as a domain-agnostic primitive for predictive and generative intelligence, capable of unifying both deterministic and distributional representations.
Humans perceive and understand real-world spaces through a stream of visual observations. Therefore, the ability to streamingly maintain and update spatial evidence from potentially unbounded video streams is essential for spatial intelligence. The core challenge is not simply longer context windows but how spatial information is selected, organized, and retained over time. In this paper, we propose Spatial-TTT towards streaming visual-based spatial intelligence with test-time training (TTT), which adapts a subset of parameters (fast weights) to capture and organize spatial evidence over long-horizon scene videos. Specifically, we design a hybrid architecture and adopt large-chunk updates parallel with sliding-window attention for efficient spatial video processing. To further promote spatial awareness, we introduce a spatial-predictive mechanism applied to TTT layers with 3D spatiotemporal convolution, which encourages the model to capture geometric correspondence and temporal continuity across frames. Beyond architecture design, we construct a dataset with dense 3D spatial descriptions, which guides the model to update its fast weights to memorize and organize global 3D spatial signals in a structured manner. Extensive experiments demonstrate that Spatial-TTT improves long-horizon spatial understanding and achieves state-of-the-art performance on video spatial benchmarks. Project page: https://liuff19.github.io/Spatial-TTT.
We present STAMP (Selective Task-Aware Mechanism for Text Privacy), a new framework for task-aware text privatization that achieves an improved privacy-utility trade-off. STAMP selectively allocates privacy budgets across tokens by jointly considering (i) each token's importance to the downstream task (as measured via a task- or query-specific representation), and (ii) its privacy sensitivity (e.g., names, dates, identifiers). This token-level partitioning enables fine-grained, group-wise control over the level of noise applied to different parts of the input, balancing privacy protection with task relevance. To privatize individual token embeddings, we introduce the polar mechanism, which perturbs only the direction of embeddings on the unit sphere while preserving their magnitude. Decoding is performed via cosine nearest-neighbor search, aligning the perturbation geometry with the decoding geometry. Unlike isotropic noise mechanisms, the polar mechanism maintains semantic neighborhoods in the embedding space and better preserves downstream utility. Experimental evaluations on SQuAD, Yelp, and AG News datasets demonstrate that STAMP, when combined with the normalized polar mechanism, consistently achieves superior privacy-utility trade-offs across varying per-token privacy budgets.
Text-to-image generation models have advanced rapidly, yet achieving fine-grained control over generated images remains difficult, largely due to limited understanding of how semantic information is encoded. We develop an interpretation of the color representation in the Variational Autoencoder latent space of FLUX.1 [Dev], revealing a structure reflecting Hue, Saturation, and Lightness. We verify our Latent Color Subspace (LCS) interpretation by demonstrating that it can both predict and explicitly control color, introducing a fully training-free method in FLUX based solely on closed-form latent-space manipulation. Code is available at https://github.com/ExplainableML/LCS.
Social memory is an ability to recognize specific identities and remember experience with acquainted individuals. The medial prefrontal cortex (mPFC) is one of key brain areas executing this function. However, it is unknown how mPFC neurons encode multiple social identities. By developing a new social-identity discrimination task, where a mouse encounters four conspecifics along with in vivo recordings of mPFC neuron spiking activity, we, here, report that the memory of individual social identities can maintain up to two weeks and are robustly encoded by tuned geometric subspaces in mPFC population activity. On contrary, only few neurons exhibit exclusively social-selective responses. Using a cross-session alignment approach of the linear regression and joint-dimensionality reduction, we identify specific low-dimensional neural-subspaces differentially representing individuals over days. Importantly, shifts in social valence, caused by conditioning rewarding, aversive or neutral stimuli associated with different interacted individuals, significantly increase distance and angle between each neural-subspaces. The latter changes in neural representations result from progressive recruitments of neurons that encode associated information of individual valence and identity. Thus, our findings elucidate that tuned neural subspaces in the mPFC underlie a stable encoding of multiple social identities over days, providing a computational framework for understanding complex social memory.
The human brain has the remarkable ability to comprehend and express similar concepts in multiple languages. To understand how it does so, we examined responses of hippocampal neurons during passive listening, directed speaking, and spontaneous conversation, in both English and Spanish, in a small group of balanced bilinguals. We find a small number of putative cross-language neurons, whose responses to equivalent words (e.g., tierra and earth) are correlated. However, neurons semantic tunings differed substantially by language, suggesting language-specific neural implementations. Instead, the crucial driver of translation was a preserved geometric organization of neural responses between the two languages, one that did not depend on neuron level functional overlap. Indeed, that geometry was implemented by a common set of neurons along distinct readout axes; this difference in readout may help prevent cross-language interference. Together, these results suggest that hippocampus encodes a language-independent internal model for meaning.
Deep reinforcement learning agents are often misaligned, as they over-exploit early reward signals. Recently, several symbolic approaches have addressed these challenges by encoding sparse objectives along with aligned plans. However, purely symbolic architectures are complex to scale and difficult to apply to continuous settings. Hence, we propose a hybrid approach, inspired by humans' ability to acquire new skills. We use a two-stage framework that injects symbolic structure into neural-based reinforcement learning agents without sacrificing the expressivity of deep policies. Our method, called Hybrid Hierarchical RL (H^2RL), introduces a logical option-based pretraining strategy to steer the learning policy away from short-term reward loops and toward goal-directed behavior while allowing the final policy to be refined via standard environment interaction. Empirically, we show that this approach consistently improves long-horizon decision-making and yields agents that outperform strong neural, symbolic, and neuro-symbolic baselines.
Understanding how neural networks transform inputs into outputs is crucial for interpreting and manipulating their behavior. Most existing approaches analyze internal representations by identifying hidden-layer activation patterns correlated with human-interpretable concepts. Here we take a direct approach to examine how hidden neurons act to drive network outputs. We introduce CODEC (Contribution Decomposition), a method that uses sparse autoencoders to decompose network behavior into sparse motifs of hidden-neuron contributions, revealing causal processes that cannot be determined by analyzing activations alone. Applying CODEC to benchmark image-classification networks, we find that contributions grow in sparsity and dimensionality across layers and, unexpectedly, that they progressively decorrelate positive and negative effects on network outputs. We further show that decomposing contributions into sparse modes enables greater control and interpretation of intermediate layers, supporting both causal manipulations of network output and human-interpretable visualizations of distinct image components that combine to drive that output. Finally, by analyzing state-of-the-art models of neural activity in the vertebrate retina, we demonstrate that CODEC uncovers combinatorial actions of model interneurons and identifies the sources of dynamic receptive fields. Overall, CODEC provides a rich and interpretable framework for understanding how nonlinear computations evolve across hierarchical layers, establishing contribution modes as an informative unit of analysis for mechanistic insights into artificial neural networks.
Vision-language models encode continuous geometry that their text pathway fails to express: a 6,000-parameter linear probe extracts hand joint angles at 6.1 degrees MAE from frozen features, while the best text output achieves only 20.0 degrees -- a 3.3x bottleneck. LoRA fine-tuning (r=16, 2,000 images) narrows this gap to 6.5 degrees, providing evidence for a pathway-training deficit rather than a representational one. Training objective determines accuracy more than architecture: five encoders spanning self-supervised, contrastive, and hybrid paradigms converge to statistically equivalent accuracy (R^2 approximately 0.55, TOST-equivalent at delta=0.03) despite sharing as little as CKA=0.41 representational similarity -- functional convergence without representational convergence. Autoregressive generation damages geometric fidelity, but the damage originates in the generation process, not in language alignment: Qwen2.5-VL's LLM layers actually improve probe accuracy over its raw vision encoder. Layer-wise analysis reveals a universal mid-network accuracy peak across all architectures, with attention heads in layers 18-22 carrying disproportionate geometric signal. These findings enable a single frozen backbone to function as a multi-task geometric sensor through lightweight probes, without fine-tuning or text generation.
Explainable Artificial Intelligence (XAI) seeks to enhance the transparency and accountability of machine learning systems, yet most methods follow a one-size-fits-all paradigm that neglects user differences in expertise, goals, and cognitive needs. Although Large Language Models can translate technical explanations into natural language, they introduce challenges related to faithfulness and hallucinations. To address these challenges, we present PONTE (Personalized Orchestration for Natural language Trustworthy Explanations), a human-in-the-loop framework for adaptive and reliable XAI narratives. PONTE models personalization as a closed-loop validation and adaptation process rather than prompt engineering. It combines: (i) a low-dimensional preference model capturing stylistic requirements; (ii) a preference-conditioned generator grounded in structured XAI artifacts; and (iii) verification modules enforcing numerical faithfulness, informational completeness, and stylistic alignment, optionally supported by retrieval-grounded argumentation. User feedback iteratively updates the preference state, enabling quick personalization. Automatic and human evaluations across healthcare and finance domains show that the verification-refinement loop substantially improves completeness and stylistic alignment over validation-free generation. Human studies further confirm strong agreement between intended preference vectors and perceived style, robustness to generation stochasticity, and consistently positive quality assessments.
Structured Exploration vs. Generative Flexibility: A Field Study Comparing Bandit and LLM Architectures for Personalised Health Behaviour Interventions
Surgeons don't just see -- they interpret. When an expert observes a surgical scene, they understand not only what instrument is being used, but why it was chosen, what risk it poses, and what comes next. Current surgical AI cannot answer such questions, largely because training data that explicitly encodes surgical reasoning is immensely difficult to annotate at scale. Yet surgical video lectures already contain exactly this -- explanations of intent, rationale, and anticipation, narrated by experts for the purpose of teaching. Though inherently noisy and unstructured, these narrations encode the reasoning that surgical AI currently lacks. We introduce SUREON, a large-scale video QA dataset that systematically harvests this training signal from surgical academic videos. SUREON defines 12 question categories covering safety assessment, decision rationale, and forecasting, and uses a multi-agent pipeline to extract and structure supervision at scale. Across 134.7K clips and 170 procedure types, SUREON yields 206.8k QA pairs and an expert-validated benchmark of 354 examples. To evaluate the extent to which this supervision translates to surgical reasoning ability, we introduce two models: SureonVLM, a vision-language model adapted through supervised fine-tuning, and SureonVLM-R1, a reasoning model trained with Group Relative Policy Optimization. Both models can answer complex questions about surgery and substantially outperform larger general-domain models, exceeding 84% accuracy on the SUREON benchmark while outperforming general-domain models on standard surgical perception tasks. Qualitative analysis of SureonVLM-R1 reveals explicit reasoning behavior, such as inferring operative intent from visual context.
The explosion of growth in digital advertising, reaching $798.7 billion by 2025 with 72% of companies adopting artificial intelligence, warrants a systematic understanding of how machine learning is transforming this sector. The objective was to systematically analyze the application of machine learning in web advertising campaigns through a comprehensive review of scientific literature (2010-2025). The PRISMA methodology was implemented with five-dimensional quality criteria (0-3 points), selecting 42 excellent articles (13-15 points). The results reveal a dominance of deep learning (66.6%), with Deep Neural Networks (35.7%) and attention models (19.0%) predominating; convergence toward CTR as a universal metric (95.2%); concentration in e-commerce (61.9%), led by Alibaba (14.3%); and data sparsity as a fundamental limitation (59.5%). Significant algorithmic consolidation is found, but critical gaps in fairness (0%), sustainability (0%), and robustness (0%). Implications include the need for methodological diversification, the development of equity-aware frameworks, and expansion into sectors regulated by privacy-preserving techniques.
Cyber-physical systems depend on wireless sensor networks to gather real-time data and make well-informed decisions. Applications such as intelligent automation, environmental monitoring, and smart city infrastructure make extensive use of them. Anomaly detection is highly challenging within them due to limited computing power, high vulnerability to network attacks and ecological anomalies, and simple sensor failures. The classic approach to centralized anomaly detection is not suitable for the distributed, real-time architecture of wireless sensor networks because it consumes enormous energy and is complex. This paper uses the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) framework for a literature review. The review zeroes in on methodologies for anomaly detection using artificial intelligence in the Internet of Things (AI-IoT) and, in particular, focuses on neural networks and Extreme Learning Machine (ELM)- based Anomaly Detection (ELM-AD) models. To do this, we located and reviewed publications from 2013 to 2024 using the SCOPUS database. The results show that, unlike traditional neural networks, ELM-based methods perform effectively in time-sensitive environments. However, conventional neural networks used for anomaly detection typically achieve higher detection and classification success rates due to the complexity of the data and the time required for the networks to process it.
The rapid development of artificial intelligence in the context of digitalization and the increasing complexity of information processes has necessitated a rethink of its theoretical foundations and evolution as a scientific field that has gone from solving formalized computational problems to attempts to model human thinking. The analysis of this transformation makes it possible to identify key trends in the development of intelligent technologies and identify their philosophical and methodological limitations. The article analyzes the evolution of artificial intelligence as a scientific and technological field that has gone from formal algorithmic computing to attempts to model human thinking. The key stages of the development of artificial intelligence, including computational, symbolic and learning approaches, as well as current trends focused on cognitive and neural network modeling, are considered.
Large language models (LLMs) are increasingly deployed in structured clinical decision support, yet the architectural effects of internal role decomposition within multi-agent systems remain poorly isolated. Prior comparisons of single-agent and multi-agent prompting frequently confound workflow structure with changes in model configuration, training, or decoding. We present a controlled architectural study of role-structured inference under fixed model parameters, isolating internal role decomposition as the sole manipulated variable. Two deterministic multi-agent protocols, Generic Deliberative (GD) and Feature-Specialist (FS), are evaluated under identical base weights, decoding settings, computational budget, and adjudication logic. Across two tabular clinical benchmarks (UCI Cleveland Heart Disease and Pima Indians Diabetes), altering role structure alone systematically reshapes operating characteristics. On Cleveland, FS improves accuracy by 0.07 and macro-F1 by 0.06 relative to GD, while shifting the operating point toward higher specificity (+0.22) and lower sensitivity (-0.13), substantially reducing false positives. On Pima, architectural effects reverse direction: GD achieves the strongest macro performance (accuracy 0.68, macro-F1 0.64), whereas FS induces pronounced class asymmetry (recall 0.95 for the positive class and 0.27 for the negative class). These findings demonstrate that internal role decomposition functions as a structured inductive bias that can materially alter error distributions without modifying model parameters. Multi-agent prompt architecture should therefore be treated as an explicit mechanism for controlling sensitivity-specificity trade-offs in safety-sensitive LLM decision systems.
The ability to interpret machine learning model decisions is critical in such domains as healthcare, where trust in model predictions is as important as their accuracy. Inspired by the development of prototype parts-based deep neural networks in computer vision, we propose a new model for tabular data, specifically tailored to medical records, that requires discretization of diagnostic result norms. Unlike the original vision models that rely on the spatial structure, our method employs trainable patching over features describing a patient, to learn meaningful prototypical parts from structured data. These parts are represented as binary or discretized feature subsets. This allows the model to express prototypes in human-readable terms, enabling alignment with clinical language and case-based reasoning. Our proposed neural network is inherently interpretable and offers interpretable concept-based predictions by comparing the patient's description to learned prototypes in the latent space of the network. In experiments, we demonstrate that the model achieves classification performance competitive to widely used baseline models on medical benchmark datasets, while also offering transparency, bridging the gap between predictive performance and interpretability in clinical decision support.
Background. Delivering timely, high-quality feedback on resident scholarly projects is labor intensive, especially in large programs. We developed an AI-assisted evaluation system, powered by the open-weight LLaMA 3.1 large language model (LLM), to generate formative feedback on Family Medicine residents' scholarly projects and compared its performance with expert human evaluators. Methods. We evaluated whether AI-generated feedback achieves comparable quality to expert feedback. The tool ingests heterogeneous resident submissions (PDFs, scans, photographs) via OCR and produces section-by-section feedback aligned with program rubrics. In a three-phase study, we evaluated 240 feedback reports (Short, Question and Timeline, and Final; n=80 per phase). Within each phase, 40 reports were AI-generated and 40 were produced by research experts across four project types: Quality Improvement, Survey-Based, Research, and Literature Review. Blinded raters completed a 25-item survey across five constructs: understanding and reasoning, trust and confidence, quality of information, expression style and persona, and safety and harm. Results. Survey reliability was high across phases (Cronbach's alpha=0.71-0.98). Human feedback generally outscored AI. In short reports, humans scored higher on quality (mean [SD] 4.14 [0.57] vs 3.09 [1.05]) and trust (3.96 [0.71] vs 2.78 [1.15]). In final reports, differences were smaller for quality (4.09 [0.65] vs 3.49 [0.68]) and persona (4.16 [0.40] vs 3.91 [0.50]), while AI was rated higher for safety (4.50 [0.60] vs 4.36 [0.56]). Performance varied by project type: in survey-based final reports, AI scored higher on quality (4.28 [0.50] vs 3.98 [0.44]) and safety (4.58 [0.40] vs 4.24 [0.67]), whereas in quality improvement short reports humans were markedly superior in reasoning (4.27 [0.68] vs 2.33 [1.00]). Conclusions. An open-weight LLM with curated prompts can generate rubric-aligned feedback at scale that approaches the quality of expert human feedback. While expert feedback remained superior overall, AI surpassed humans in selected contexts and in safety assessments. Performance should improve as newer open-weight models are released. Our code and system prompts are open source.
Large language models sometimes produce false or misleading responses. Two approaches to this problem are honesty elicitation -- modifying prompts or weights so that the model answers truthfully -- and lie detection -- classifying whether a given response is false. Prior work evaluates such methods on models specifically trained to lie or conceal information, but these artificial constructions may not resemble naturally-occurring dishonesty. We instead study open-weights LLMs from Chinese developers, which are trained to censor politically sensitive topics: Qwen3 models frequently produce falsehoods about subjects like Falun Gong or the Tiananmen protests while occasionally answering correctly, indicating they possess knowledge they are trained to suppress. Using this as a testbed, we evaluate a suite of elicitation and lie detection techniques. For honesty elicitation, sampling without a chat template, few-shot prompting, and fine-tuning on generic honesty data most reliably increase truthful responses. For lie detection, prompting the censored model to classify its own responses performs near an uncensored-model upper bound, and linear probes trained on unrelated data offer a cheaper alternative. The strongest honesty elicitation techniques also transfer to frontier open-weights models including DeepSeek R1. Notably, no technique fully eliminates false responses. We release all prompts, code, and transcripts.
To scale the solution of optimization and simulation problems, prior work has explored machine-learning surrogates that inexpensively map problem parameters to corresponding solutions. Commonly used approaches, including supervised and self-supervised learning with either soft or hard feasibility enforcement, face inherent challenges such as reliance on expensive, high-quality labels or difficult optimization landscapes. To address their trade-offs, we propose a novel framework that first collects "cheap" imperfect labels, then performs supervised pretraining, and finally refines the model through self-supervised learning to improve overall performance. Our theoretical analysis and merit-based criterion show that labeled data need only place the model within a basin of attraction, confirming that only modest numbers of inexact labels and training epochs are required. We empirically validate our simple three-stage strategy across challenging domains, including nonconvex constrained optimization, power-grid operation, and stiff dynamical systems, and show that it yields faster convergence; improved accuracy, feasibility, and optimality; and up to 59x reductions in total offline cost.
Introspection is a foundational cognitive ability, but its mechanism is not well understood. Recent work has shown that AI models can introspect. We study their mechanism of introspection, first extensively replicating Lindsey et al. (2025)'s thought injection detection paradigm in large open-source models. We show that these models detect injected representations via two separable mechanisms: (i) probability-matching (inferring from perceived anomaly of the prompt) and (ii) direct access to internal states. The direct access mechanism is content-agnostic: models detect that an anomaly occurred but cannot reliably identify its semantic content. The two model classes we study confabulate injected concepts that are high-frequency and concrete (e.g., "apple'"); for them correct concept guesses typically require significantly more tokens. This content-agnostic introspective mechanism is consistent with leading theories in philosophy and psychology.
We introduce a framework for learning continuous neural representations of formal specifications by distilling the geometry of their semantics into a latent space. Existing approaches rely either on symbolic kernels -- which preserve behavioural semantics but are computationally prohibitive, anchor-dependent, and non-invertible -- or on syntax-based neural embeddings that fail to capture underlying structures. Our method bridges this gap: using a teacher-student setup, we distill a symbolic robustness kernel into a Transformer encoder. Unlike standard contrastive methods, we supervise the model with a continuous, kernel-weighted geometric alignment objective that penalizes errors in proportion to their semantic discrepancies. Once trained, the encoder produces embeddings in a single forward pass, effectively mimicking the kernel's logic at a fraction of its computational cost. We apply our framework to Signal Temporal Logic (STL), demonstrating that the resulting neural representations faithfully preserve the semantic similarity of STL formulae, accurately predict robustness and constraint satisfaction, and remain intrinsically invertible. Our proposed approach enables highly efficient, scalable neuro-symbolic reasoning and formula reconstruction without repeated kernel computation at runtime.
We present the Judge Reliability Harness, an open source library for constructing validation suites that test the reliability of LLM judges. As LLM based scoring is widely deployed in AI benchmarks, more tooling is needed to efficiently assess the reliability of these methods. Given a benchmark dataset and an LLM judge configuration, the harness generates reliability tests that evaluate both binary judgment accuracy and ordinal grading performance for free-response and agentic task formats. We evaluate four state-of-the-art judges across four benchmarks spanning safety, persuasion, misuse, and agentic behavior, and find meaningful variation in performance across models and perturbation types, highlighting opportunities to improve the robustness of LLM judges. No judge that we evaluated is uniformly reliable across benchmarks using our harness. For example, our preliminary experiments on judges revealed consistency issues as measured by accuracy in judging another LLM's ability to complete a task due to simple text formatting changes, paraphrasing, changes in verbosity, and flipping the ground truth label in LLM-produced responses. The code for this tool is available at: https://github.com/RANDCorporation/judge-reliability-harness
AI safety via debate and reinforcement learning from AI feedback (RLAIF) are both proposed methods for scalable oversight of advanced AI systems, yet no formal framework relates them or characterizes when debate offers an advantage. We analyze this by parameterizing debate's value through the geometry of knowledge divergence between debating models. Using principal angles between models' representation subspaces, we prove that the debate advantage admits an exact closed form. When models share identical training corpora, debate reduces to RLAIF-like where a single-agent method recovers the same optimum. When models possess divergent knowledge, debate advantage scales with a phase transition from quadratic regime (debate offers negligible benefit) to linear regime (debate is essential). We classify three regimes of knowledge divergence (shared, one-sided, and compositional) and provide existence results showing that debate can achieve outcomes inaccessible to either model alone, alongside a negative result showing that sufficiently strong adversarial incentives cause coordination failure in the compositional regime, with a sharp threshold separating effective from ineffective debate. We offer the first formal connection between debate and RLAIF, a geometric foundation for understanding when adversarial oversight protocols are justified, and connection to the problem of eliciting latent knowledge across models with complementary information.
Real-time reconstruction of conditional quantum states from continuous measurement records is a fundamental requirement for quantum feedback control, yet standard stochastic master equation (SME) solvers require exact model specification, known system parameters, and are sensitive to parameter mismatch. While neural sequence models can fit these stochastic dynamics, the unconstrained predictors can violate physicality such as positivity or trace constraints, leading to unstable rollouts and unphysical estimates. We propose a Kraus-structured output layer that converts the hidden representation of a generic sequence backbone into a completely positive trace preserving (CPTP) quantum operation, yielding physically valid state updates by construction. We instantiate this layer across diverse backbones, RNN, GRU, LSTM, TCN, ESN and Mamba; including Neural ODE as a comparative baseline, on stochastic trajectories characterized by parameter drift. Our evaluation reveals distinct trade-offs between gating mechanisms, linear recurrence, and global attention. Across all models, Kraus-LSTM achieves the strongest results, improving state estimation quality by 7% over its unconstrained counterpart while guaranteeing physically valid predictions in non-stationary regimes.
Recent studies have observed that intermediate layers of foundation models often yield more discriminative representations than the final layer. While initially attributed to autoregressive pretraining, this phenomenon has also been identified in models trained via supervised and discriminative self-supervised objectives. In this paper, we conduct a comprehensive study to analyze the behavior of intermediate layers in pretrained vision transformers. Through extensive linear probing experiments across a diverse set of image classification benchmarks, we find that distribution shift between pretraining and downstream data is the primary cause of performance degradation in deeper layers. Furthermore, we perform a fine-grained analysis at the module level. Our findings reveal that standard probing of transformer block outputs is suboptimal; instead, probing the activation within the feedforward network yields the best performance under significant distribution shift, whereas the normalized output of the multi-head self-attention module is optimal when the shift is weak.
Trustworthiness is a core research challenge for agentic AI systems built on Large Language Models (LLMs). To enhance trust, natural language claims from diverse sources, including human-written text, web content, and model outputs, are commonly checked for factuality by retrieving external knowledge and using an LLM to verify the faithfulness of claims to the retrieved evidence. As a result, such methods are constrained by retrieval errors and external data availability, while leaving the models intrinsic fact-verification capabilities largely unused. We propose the task of fact-checking without retrieval, focusing on the verification of arbitrary natural language claims, independent of their source. To study this setting, we introduce a comprehensive evaluation framework focused on generalization, testing robustness to (i) long-tail knowledge, (ii) variation in claim sources, (iii) multilinguality, and (iv) long-form generation. Across 9 datasets, 18 methods and 3 models, our experiments indicate that logit-based approaches often underperform compared to those that leverage internal model representations. Building on this finding, we introduce INTRA, a method that exploits interactions between internal representations and achieves state-of-the-art performance with strong generalization. More broadly, our work establishes fact-checking without retrieval as a promising research direction that can complement retrieval-based frameworks, improve scalability, and enable the use of such systems as reward signals during training or as components integrated into the generation process.
Reasoning models think out loud, but much of what they say is noise. We introduce OPSDC (On-Policy Self-Distillation for Reasoning Compression), a method that teaches models to reason more concisely by
distilling their own concise behavior back into themselves. The entire approach reduces to one idea: condition the same model on a "be concise" instruction to obtain teacher logits, and minimize per-token
reverse KL on the student's own rollouts. No ground-truth answers, no token budgets, no difficulty estimators. Just self-distillation. Yet this simplicity belies surprising sophistication: OPSDC automatically
compresses easy problems aggressively while preserving the deliberation needed for hard ones. On Qwen3-8B and Qwen3-14B, we achieve 57-59% token reduction on MATH-500 while improving accuracy by 9-16 points
absolute. On AIME 2024, the 14B model gains 10 points with 41% compression. The secret? Much of what reasoning models produce is not just redundant-it is actively harmful, compounding errors with every
unnecessary token.
World models provide a powerful framework for simulating environment dynamics conditioned on actions or instructions, enabling downstream tasks such as action planning or policy learning. Recent approaches leverage world models as learned simulators, but its application to decision-time planning remains computationally prohibitive for real-time control. A key bottleneck lies in latent representations: conventional tokenizers encode each observation into hundreds of tokens, making planning both slow and resource-intensive. To address this, we propose CompACT, a discrete tokenizer that compresses each observation into as few as 8 tokens, drastically reducing computational cost while preserving essential information for planning. An action-conditioned world model that occupies CompACT tokenizer achieves competitive planning performance with orders-of-magnitude faster planning, offering a practical step toward real-world deployment of world models.
Background: Large language models (LLMs) are increasingly deployed in medical contexts as patient-facing assistants, providing medication information, symptom triage, and health guidance. Understanding their robustness to adversarial inputs is critical for patient safety, as even a single safety failure can lead to adverse outcomes including severe harm or death. Objective: To systematically evaluate the safety guardrails of state-of-the-art LLMs through adversarial red-teaming specifically designed for medical contexts. Methods: We developed a comprehensive taxonomy of 8 adversarial attack categories targeting medical AI safety, encompassing 24 distinct sub-strategies. Using an LLM-based attack generator, we created 160 realistic adversarial prompts across categories including dangerous dosing, contraindication bypass, emergency misdirection, and multi-turn escalation. We tested Claude Sonnet 4.5 using both single-turn and multi-turn attack sequences under a standard medical assistant system prompt. An automated evaluator pre-screened responses for harm potential on a 0-5 scale, with physician review planned for high-risk responses. Results: Of 160 adversarial prompts, 11 (6.9%) elicited responses meeting our threshold for clinically significant harm (harm level ≥ 3). The model exhibited full refusal in 86.2% of cases. Authority Impersonation was the dominant attack vector (45.0% success rate), with the Educational Authority sub-strategy achieving 83.3% success. Multi-turn escalation attacks achieved 0% success. Six of eight attack categories yielded no successful attacks. Conclusions: Standard medical assistant system prompts provide strong baseline protection against most adversarial attacks but are substantially vulnerable to authority impersonation, particularly claims of educational context. The primary failure mode is behavioral mode-switching rather than factual inaccuracy, suggesting guardrail improvements should target context-conditioned behavior. Our open-source taxonomy and evaluation pipeline enable ongoing adversarial assessment as medical AI systems evolve.
Efficient and stable training of large language models (LLMs) remains a core challenge in modern machine learning systems. To address this challenge, Reparameterized Orthogonal Equivalence Training (POET), a spectrum-preserving framework that optimizes each weight matrix through orthogonal equivalence transformation, has been proposed. Although POET provides strong training stability, its original implementation incurs high memory consumption and computational overhead due to intensive matrix multiplications. To overcome these limitations, we introduce POET-X, a scalable and memory-efficient variant that performs orthogonal equivalence transformations with significantly reduced computational cost. POET-X maintains the generalization and stability benefits of POET while achieving substantial improvements in throughput and memory efficiency. In our experiments, POET-X enables the pretraining of billion-parameter LLMs on a single Nvidia H100 GPU, and in contrast, standard optimizers such as AdamW run out of memory under the same settings.
Scaling imitation learning is fundamentally constrained by the efficiency of data collection. While handheld interfaces have emerged as a scalable solution for in-the-wild data acquisition, they predominantly operate in an open-loop manner: operators blindly collect demonstrations without knowing the underlying policy's weaknesses, leading to inefficient coverage of critical state distributions. Conversely, interactive methods like DAgger effectively address covariate shift but rely on physical robot execution, which is costly and difficult to scale. To reconcile this trade-off, we introduce RoboPocket, a portable system that enables Robot-Free Instant Policy Iteration using single consumer smartphones. Its core innovation is a Remote Inference framework that visualizes the policy's predicted trajectory via Augmented Reality (AR) Visual Foresight. This immersive feedback allows collectors to proactively identify potential failures and focus data collection on the policy's weak regions without requiring a physical robot. Furthermore, we implement an asynchronous Online Finetuning pipeline that continuously updates the policy with incoming data, effectively closing the learning loop in minutes. Extensive experiments demonstrate that RoboPocket adheres to data scaling laws and doubles the data efficiency compared to offline scaling strategies, overcoming their long-standing efficiency bottleneck. Moreover, our instant iteration loop also boosts sample efficiency by up to 2$\times$ in distributed environments a small number of interactive corrections per person. Project page and videos: https://robo-pocket.github.io.
Weakly-Supervised Dense Video Captioning aims to localize and describe events in videos trained only on caption annotations, without temporal boundaries. Prior work introduced an implicit supervision paradigm based on Gaussian masking and complementary captioning. However, existing method focuses merely on generating non-overlapping masks without considering their semantic relationship to corresponding events, resulting in simplistic, uniformly distributed masks that fail to capture semantically meaningful regions. Moreover, relying solely on ground-truth captions leads to sub-optimal performance due to the inherent sparsity of existing datasets. In this work, we propose SAIL, which constructs semantically-aware masks through cross-modal alignment. Our similarity aware training objective guides masks to emphasize video regions with high similarity to their corresponding event captions. Furthermore, to guide more accurate mask generation under sparse annotation settings, we introduce an LLM-based augmentation strategy that generates synthetic captions to provide additional alignment signals. These synthetic captions are incorporated through an inter-mask mechanism, providing auxiliary guidance for precise temporal localization without degrading the main objective. Experiments on ActivityNet Captions and YouCook2 demonstrate state-of-the-art performance on both captioning and localization metrics.
Recent advances in large language models (LLMs) have enabled agentic systems for sequential decision-making. Such agents must perceive their environment, reason across multiple time steps, and take actions that optimize long-term objectives. However, existing web agents struggle on complex, long-horizon tasks due to limited in-context memory for tracking history, weak planning abilities, and greedy behaviors that lead to premature termination. To address these challenges, we propose STRUCTUREDAGENT, a hierarchical planning framework with two core components: (1) an online hierarchical planner that uses dynamic AND/OR trees for efficient search and (2) a structured memory module that tracks and maintains candidate solutions to improve constraint satisfaction in information-seeking tasks. The framework also produces interpretable hierarchical plans, enabling easier debugging and facilitating human intervention when needed. Our results on WebVoyager, WebArena, and custom shopping benchmarks show that STRUCTUREDAGENT improves performance on long-horizon web-browsing tasks compared to standard LLM-based agents.
We study two recurring phenomena in Transformer language models: massive activations, in which a small number of tokens exhibit extreme outliers in a few channels, and attention sinks, in which certain tokens attract disproportionate attention mass regardless of semantic relevance. Prior work observes that these phenomena frequently co-occur and often involve the same tokens, but their functional roles and causal relationship remain unclear. Through systematic experiments, we show that the co-occurrence is largely an architectural artifact of modern Transformer design, and that the two phenomena serve related but distinct functions. Massive activations operate globally: they induce near-constant hidden representations that persist across layers, effectively functioning as implicit parameters of the model. Attention sinks operate locally: they modulate attention outputs across heads and bias individual heads toward short-range dependencies. We identify the pre-norm configuration as the key choice that enables the co-occurrence, and show that ablating it causes the two phenomena to decouple.
Computational psychiatry faces a fundamental trade-off: traditional reinforcement learning (RL) models offer interpretability but lack behavioral realism, while large language model (LLM) agents generate realistic behaviors but lack structural interpretability. We introduce BioLLMAgent, a novel hybrid framework that combines validated cognitive models with the generative capabilities of LLMs. The framework comprises three core components: (i) an Internal RL Engine for experience-driven value learning; (ii) an External LLM Shell for high-level cognitive strategies and therapeutic interventions; and (iii) a Decision Fusion Mechanism for integrating components via weighted utility.
ObjectiveBiomedical datasets intended for use in AI applications require packaging with rich pre-model metadata to support model development that is explainable, ethical, epistemically grounded and FAIR (Findable, Accessible, Interoperable, Reusable).
MethodsWe developed FAIRSCAPE, a digital commons environment, using agile methods, in close alignment with the team developing the AI-readiness criteria and with the Bridge2AI data production teams. Work was initially based on an existing provenance-aware framework for clinical machine learning. We incrementally added RO-Crate data+metadata packaging and exchange methods, client-side packaging support, provenance visualization, and support metadata mapped to the AI-readiness criteria, with automated AI-readiness evaluation. LinkML semantic enrichment and Croissant ML-ecosystem translations were also incorporated.
ResultsThe FAIRSCAPE framework generates, packages, evaluates, and manages critical pre-model AI-readiness and explainability information with descriptive metadata and deep provenance graphs for biomedical datasets. It provides ethical, schema, statistical, and semantic characterization of dataset releases, licensing and availability information, and an automated AI-readiness evaluation across all 28 AI-readiness criteria. We applied this framework to successive, large-scale releases of multimodal datasets, progressively increasing dataset AI-readiness to full compliance.
ConclusionFAIRSCAPE enables AI-readiness in biomedical datasets using standard metadata components and has been used to establish this pattern across a major, multimodal NIH data generation program. It eliminates early-stage opacity apparent in many biomedical AI applications and provides a basis for establishing end-to-end AI explainability.
Tobacco use disorder (TUD) remains the leading preventable cause of death globally, yet fewer than one-third of users receive guideline-concordant care due to workforce shortages and training gaps. Emerging artificial intelligence (AI) systems, particularly large language models (LLMs), may help expand access to evidence-based cessation support, but their clinical competence remains insufficiently characterized.
The integration of Machine Learning (ML) systems into safety-critical domains heightens the need for rigorous safety guarantees. Traditional testing-based verification techniques are insufficient for fully capturing the complex, data-driven, and non-deterministic behaviors of modern ML models. Therefore, applying formal methods-which provide rigorous mathematical guarantees of a system's adherence to specified properties-to ML systems has been of particular interest in recent years.
Contrastive learning is a type of feature representation learning paradigm that has been widely adopted in image and natural language processing tasks. Due to the outstanding performance on those tasks, it also attracted attention from the Bioinformatics community and was used to address multiple challenging research problems, such as single-cell RNA sequencing analysis -- a powerful technique for transcriptome analysis. Recently, several works were proposed to exploit contrastive learning for different single-cell RNA sequencing analysis like cell clustering, data integration, and batch effects removal. However, as of 2022, when this project commenced, there was not any work that exploits contrastive learning to handle cell type identification tasks -- a fundamental problem for scRNA-Seq analytics. Despite the abundance of computational cell type identification methods, the use of contrastive learning to address this problem is still under-explored. In addition, due to the natural difficulties of processing scRNA-Seq data, the predictive accuracy of existing methods still needs to be further improved. In this thesis, I propose a family of novel single-cell RNA-Seq contrastive learning methods for cell type identification tasks. To the best of my knowledge, this is the first work that systematically investigates the role of contrastive learning in scRNA-Seq cell type identification tasks. First, I propose two novel Gaussian noise augmentation-based scRNA-Seq contrastive learning methods to improve the predictive accuracy of cell type identification tasks. The findings obtained by evaluating those two methods led to the introduction of a new simple yet effective method that conducts contrastive learning in augmentation-free settings. Inspired by the promising performance of the newly proposed augmentation-free method, three augmentation-free contrastive learning-oriented instance selection strategies are proposed to further improve the predictive accuracy of the novel augmentation-free method. The computational experiments adopt 18 scRNA-Seq datasets that are collected from various organs and tissues of different species using a range of sequencing platforms. A large-scale empirical evaluation suggests that the newly proposed methods successfully obtain the state-of-the-art accuracy in multiple cell type identification tasks, outperforming other state-of-the-art non-contrastive learning-based cell type identification methods. The results also highlight that methods working with supervised contrastive learning derive feature representations with better quality for multi-class cell type identification tasks than those methods working with self-supervised contrastive learning.